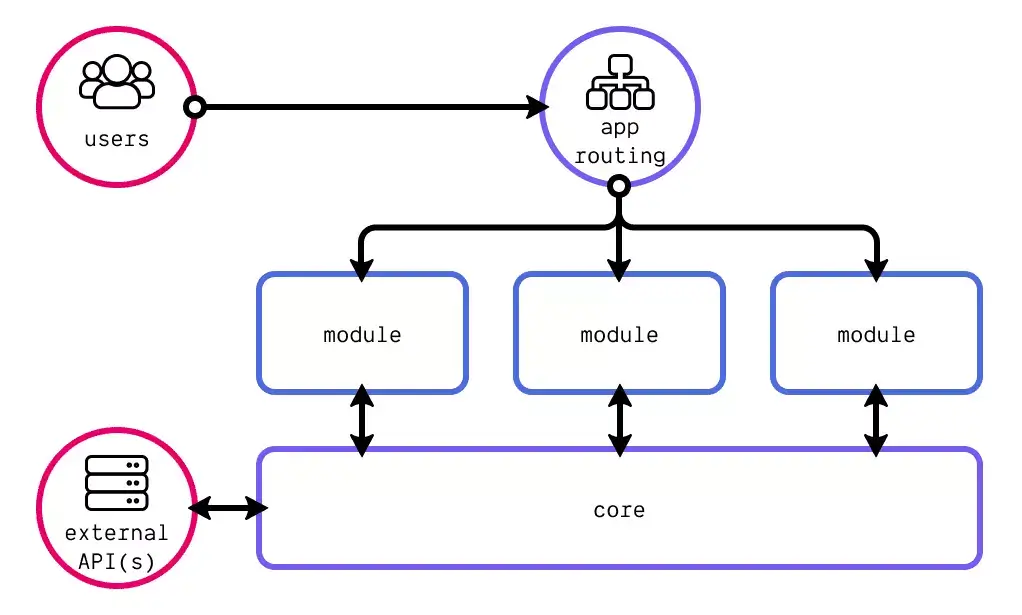
Finaps’ CTO as a service offering
In the dynamic world of startups, entrepreneurs armed with industry expertise often come up with the most promising ideas, recognising the role of software and data as not just expenses, but as generators of revenue. They understand the significance of technology in executing core business activities, Their innovative vision connects technology to their industry in a unique way. This often leads to the birth of a new startup. However, when there is no Chief Technology Officer (CTO) among the founders, their biggest challenge is finding one. This is where Finaps enters the picture, offering a unique solution: acting as an external Chief Technology Officer (CTO).